Given a sequence of positive numbers, a segment is defined to be a consecutive subsequence. For example, given the sequence { 0.1, 0.2, 0.3, 0.4 }, we have 10 segments: (0.1) (0.1, 0.2) (0.1, 0.2, 0.3) (0.1, 0.2, 0.3, 0.4) (0.2) (0.2, 0.3) (0.2, 0.3, 0.4) (0.3) (0.3, 0.4) and (0.4).
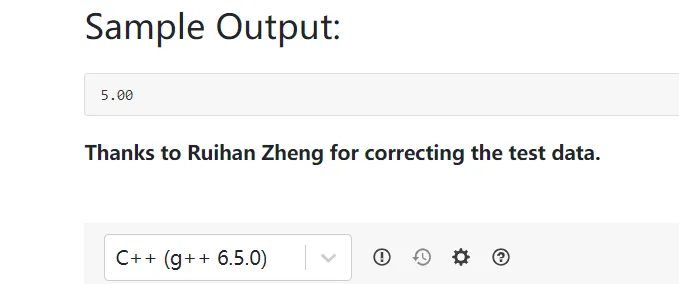
Now given a sequence, you are supposed to find the sum of all the numbers in all the segments. For the previous example, the sum of all the 10 segments is 0.1 + 0.3 + 0.6 + 1.0 + 0.2 + 0.5 + 0.9 + 0.3 + 0.7 + 0.4 = 5.0.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N, the size of the sequence which is no more than 105. The next line contains N positive numbers in the sequence, each no more than 1.0, separated by a space.
Output Specification:
For each test case, print in one line the sum of all the numbers in all the segments, accurate up to 2 decimal places.
intmain(){ int N; cin >> N; vector<double> seq(N + 1); for (int i = 1; i <= N; i++) { scanf("%lf", &seq[i]); } double sum = seq[N]; for (int i = N - 1; i > 0; i--) { seq[i] = seq[i + 1] + seq[i] * (N - i + 1); sum += seq[i]; } printf("%.2f", sum); return0; }
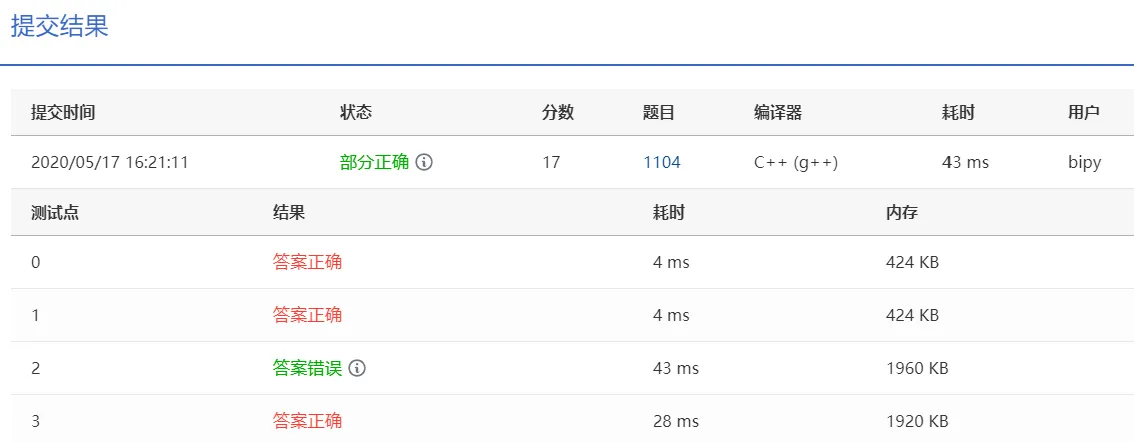
结果
测试点 2,也就是最大数量测试($10^5$)答案错误,这一点让我比较疑惑。
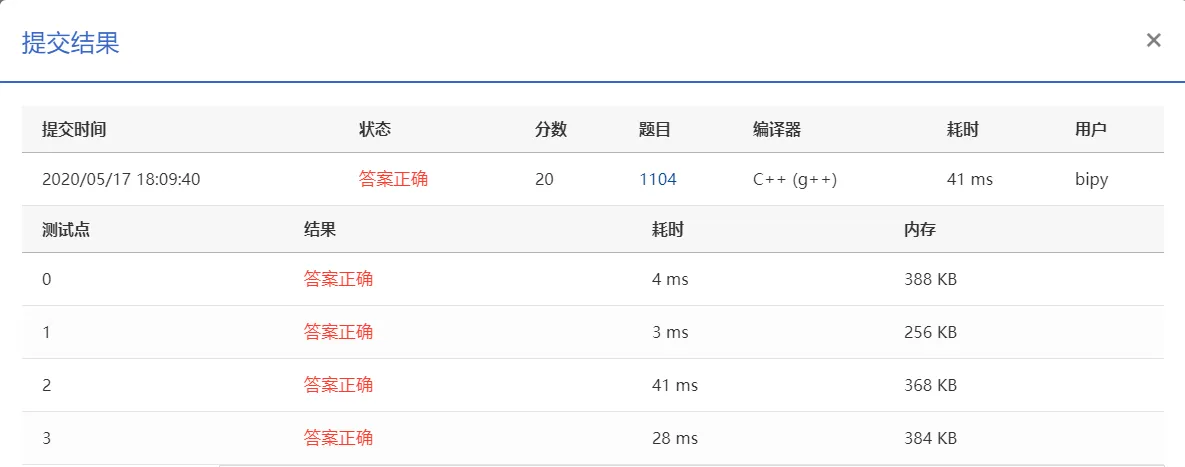
对结果的讨论
确认代码无误后,我尝试在网上寻找答案,结果发现几乎所有人都使用了下面这种算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include<iostream> usingnamespace std;
intmain(){ int N; cin >> N; double v, ans = 0; for (int i = 1; i <= N; i++) { scanf("%lf", &v); ans += v * i * (N - i + 1); } printf("%.2f", ans); return0; }
// 我的方法 doublefun1(vector<double> &seq){ int N = seq.size() - 1; double sum = seq[N]; for (int i = N - 1; i > 0; i--) { seq[i] = seq[i + 1] + seq[i] * (N - i + 1); sum += seq[i]; } return sum; }
// 标准答案 doublefun2(vector<double> &seq){ double ans = 0; int N = seq.size() - 1; for (int i = 1; i <= N; i++) { ans += seq[i] * i * (N - i + 1); } return ans; }
intmain(){ srand(unsigned(time(NULL))); constint N = 100000; // 此处 N 设置为题目要求最大值 vector<double> seq(N + 1); int cnt = 0; // 测试计数 while (true) { cout << cnt++ << endl; for (int i = 1; i <= N; i++) { // 使用3位随机小数 seq[i] = 0.001 * (rand() % 1000); } // 如果两种方法答案误差在0.01以上(题目条件) double a = fun2(seq), b = fun1(seq); if (fabs(a - b) > 0.01) { printf("%.2f\n", a); printf("%.2f\n", b); } } return0; }
// 我的方法 longlongfun1(vector<longlong> &seq){ int N = seq.size() - 1; longlong sum = seq[N]; for (int i = N - 1; i > 0; i--) { seq[i] = seq[i + 1] + seq[i] * (N - i + 1); sum += seq[i]; } return sum; }
// 标准答案 longlongfun2(vector<longlong> &seq){ longlong ans = 0; int N = seq.size() - 1; for (int i = 1; i <= N; i++) { ans += seq[i] * i * (N - i + 1); } return ans; }
intmain(){ srand(unsigned(time(NULL))); constint N = 100000; // 此处 N 设置为题目要求最大值 vector<longlong> seq(N + 1); int cnt = 0; // 测试计数 while (true) { cout << cnt++ << endl; for (int i = 1; i <= N; i++) { // 使用3位随机数 seq[i] = rand() % 1000; } // 如果两种方法答案不相等 longlong a = fun2(seq), b = fun1(seq); if (a != b) { printf("%lld\n", a); printf("%lld\n", b); } } return0; }
intmain(){ int N; cin >> N; double v; longlong ans = 0; for (int i = 1; i <= N; i++) { scanf("%lf", &v); ans += (longlong) (v * 1000) * i * (N - i + 1); } printf("%.2f", ans / 1000.0); return0; }